用动量梯度下降法训练BP网络 已知输入向量为P=[-1,-2,3,1 -1,1,5,3],目标输出为T=[-1,-1,1,1]。
”5输入_1输出__bp momentum_bp 动量梯度下降 梯度下降法“ 的搜索结果
%例1 采用动量梯度下降算法训练 BP 网络。
这主要是因为梯度下降法在遇到局部最优时,毫无办法为了解决跳出局部最优,动量梯度下降法为此模仿物体从高处滚到低处的原理,由于物体具有动量,遇到小坑时会由于原有动量而跃出小坑,因此,动量梯度下降法在迭代的...

基于有动量和自适应lr梯度下降法BP神经网络的城市用电量预测技术.pdf
用动量梯度下降算法训练BP网络 使用的主要函数如下: NEWFF——生成一个新的前向神经网络 TRAIN——对BP神经网络进行训练 SIM——对BP神经网络进行仿真
本篇博客来自其他博客以及论文消化吸收,假如读者熟悉BP网络正向传播,但是一直疑惑反向传播,那么可以继续看。 资料来源: https://blog.csdn.net/SZU_Hadooper/article/details/78619575 ... ...
BP神经网络模型及梯度下降法
标签: BP
BP神经网络模型及梯度下降法 BP(Back Propagation)网络是1985年由Rumelhart和McCelland为首的科学家小组提出,是一种按误差逆传播算法训练的多层前馈网络,是目前应用最广泛的神经网络模型之一。 BP网络能...
采用动量梯度下降算法训练 BP 网络 matlab代码
BP神经网络的java源代码,采用动量梯度下降法
这主要是因为梯度下降法在遇到局部最优时,毫无办法为了解决跳出局部最优,动量梯度下降法为此模仿物体从高处滚到低处的原理,由于物体具有动量,遇到小坑时会由于原有动量而跃出小坑,因此,动量梯度下降法在迭代的...
神经网络的运行以及梯度下降法和BP算法 1 神经网络的运作 神经网络运作过程分为学习和工作两种状态。 1.1 神经网络学习状态 神经网络的学习主要是指使用学习算法来调整神经元间的连接权,使得网络输出更符合实际。...
在求解机器学习算法的模型参数,即无约束优化问题时,梯度下降(Gradient Descent)是最常采用的方法之一,另一种常用的方法是最小二乘法,关于最小二乘法,可参考笔者的上一篇博客 BP 神经网络中的基础算法之一 ...


在这儿,我们再作个形象的类比,如果把这个走法类比为力,那么完整的三要素就是步长(走多少)、方向、出发点,这样形象的比喻,让我们对梯度问题的解决豁然开朗,出发点很重要,是初始化时重点要考虑的,而方向、...
BP算法与梯度下降算法
标签: BP
作者:胡逸夫链接:https://www.zhihu.com/question/27239198/answer/89853077来源:知乎著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。BackPropagation算法是多层神经网络的训练中举足轻重...

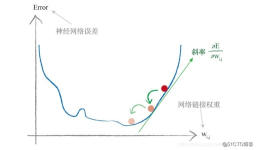
%是否使用梯度下降法进行局部搜索的控制参数 IfLocalSearch=0; %...经过 10000 次训练后,traningdm 网络的输出误差与 traningd 训练算法的结果差不多, -9- 网络误差的收敛速度也非常慢。Traningdm 是动量梯度下降...
本文
(1) traingd:基本梯度下降法,收敛速度比较慢。 (2) traingda:自适应学习率的梯度下降法 (3) traingdm:带有动量项的梯度下降法, 通常要比traingd 速度快。 (4) traingdx: 带有动量项的自适应学习算法, ...
BP_momentum.zip
标签: BP
一阶梯度下降算法是学习BP神经网络的入门基础,而动量梯度下降法是一阶梯度下降算法的优化算法,理解其原理对于学习机器学习很重要。
图4.2 BP神经网络程序框图(3)网络训练及检验BP网络采用梯度下降法来降低网络的训练误差,考虑到基坑降水地面沉降范围内沉降量变化幅度较小的特点,训练时以训练目标取0.001为控制条件,考虑到网络的结构比较复杂,...
5:批量梯度下降法(BGD)和随机梯度下降法(SGD)的代码实现Matlab版 2016年10月19日 10:17:28 Eric2016_Lv 阅读数:3379 ...
神经网络基础知识简介 # 一、机器学习 机器学习用一句话概括就是“根据数据找函数”。... 举个例子,假设女生择偶时主要根据“高富帅”来决定是否要在一起,那么先通过采访或者问卷调查得到一大批数据样本,每个...
本质是线, 一般用参数方程来描述, 这一条线一共有三个维度信息。

function ww = gradient_descent(training_example,eta) [m,n] = size(training_... %输入量个数 ,最后一项是目标值,所以少一个 for i=1:num_x %初始化权值矩阵在(-1,1),这个相对较好 w(i) = 2*(rand()-0.5)
推荐文章
- 小说网站系统源码|PHP付费小说网站源码带app-程序员宅基地
- Swift编码规范_swift 正则判断文件类型-程序员宅基地
- 关于shell 中return用法解释(转)_shell return-程序员宅基地
- Linux编译宏BUILD_BUG_ON_ZERO-程序员宅基地
- c51语言单片机打铃系统设计,基于单片机的自动打铃系统的设计-程序员宅基地
- 在php中使用SMTP通过密抄批量发送邮件-程序员宅基地
- python数据清洗+数据可视化_python课程题目数据清除与可视化-程序员宅基地
- 【11g】3.3 Oracle自动存储管理存储配置_oraclestorageoptions-程序员宅基地
- signature=b2f9171fa2897cefe08a669efaf58433,FULFILLMENT TRACKING IN ASSET-DRIVEN WORKFLOW MODELING-程序员宅基地
- 宜兴市计算机中等学校,重磅!江苏省陶都中等专业学校正式揭牌!-程序员宅基地